

Summarize this post with AI
An AI-ready data playbook is a structured, repeatable system that prepares your organisation's data for reliable, scalable use with large language models and machine learning pipelines. Think of it as the operating manual between your raw data and your deployed AI it covers ingestion, cleaning, labelling, indexing, retrieval, monitoring, and governance in one cohesive workflow. Traditional data science focuses on batch analytics: you clean historical data, train a model, and ship it. AI-ready data engineering is fundamentally different. LLMs need continuously refreshed, structured, semantically coherent inputs. A stale embedding is as dangerous as no embedding at all.
Why Businesses Need This Now
According to Gartner, over 85% of AI projects fail to reach production and poor data quality is cited as the leading cause in 60% of those failures. The good news: a well-executed AI data readiness assessment methodology can cut time-to-deployment by 40–60%.
Whether you're exploring Veda AI for data analytics or building a custom LLM stack, the playbook principles remain the same: assess, structure, label, retrieve, monitor, and govern.
Key Takeaway AI readiness isn't a one-time project it's an ongoing operational discipline. Every layer of your data stack must be designed for continuous AI consumption, not just periodic batch exports.
The Evolution of Data Science AI (2020–2026)
Five years ago, "AI-ready data" meant having a clean CSV and a trained classifier. Today it means something dramatically more complex and more powerful.
Pre-2022: The Batch Era
Most organisations treated data pipelines as ETL (Extract, Transform, Load) workflows serving BI dashboards. AI was an afterthought. Data scientists wrote bespoke Python scripts to extract features manually, and model retraining was a quarterly event at best.
2022–2024: The LLM Explosion
The release of GPT-3.5 and subsequent open-source models changed everything. Suddenly, unstructured text customer emails, support tickets, contracts, PDFs — became valuable AI input. But organisations quickly discovered that feeding raw documents into an LLM produced hallucinations, not insights. The demand for RAG pipelines was born.
2025–2026: Real-Time, Governed, Multimodal
We now operate in an era where AI systems consume streaming data, generate embeddings in real time, and serve responses grounded in up-to-the-minute knowledge bases. Building an AI-ready data infrastructure today requires orchestration tools that didn't exist three years ago. Vector databases, embedding pipelines, and drift monitors have graduated from research tools to production essentials.
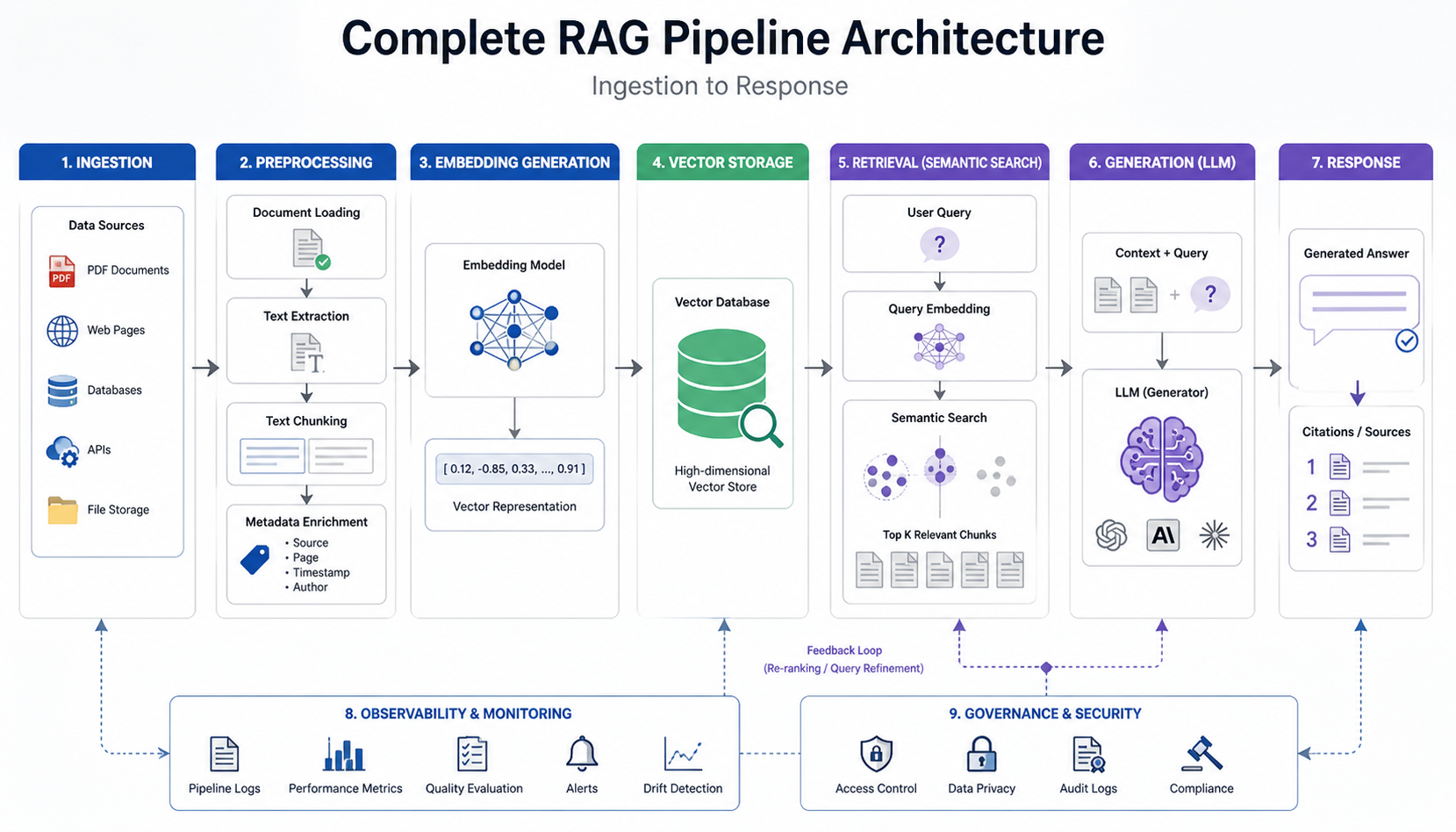
RAG Data Pipeline Architecture: The Core Engine
If there's one concept at the heart of every AI-ready data playbook, it's the RAG (Retrieval-Augmented Generation) pipeline. Understanding what is a RAG pipeline is non-negotiable for any team deploying LLMs on proprietary data.
What Is a RAG Pipeline?
A RAG pipeline is a two-stage architecture that first retrieves relevant documents from a knowledge base, then feeds them as context to an LLM to generate a grounded, accurate response. Without retrieval, LLMs can only draw on their training data — which quickly becomes stale and hallucination-prone. With RAG, your model answers from your data, in real time.
RAG Pipeline Implementation: The 5 Core Stages
Step 1: Document Ingestion & Chunking Raw documents (PDFs, wikis, databases) are ingested and split into semantically coherent chunks typically 256–512 tokens. Poor chunking is the #1 cause of irrelevant RAG responses. Tools: LangChain Document Loaders, Unstructured.io, Apache Tika.
Step 2: Embedding Generation Each chunk is converted into a dense vector representation using an embedding model (e.g., text-embedding-3-large, BGE-M3, or Cohere Embed). These vectors encode semantic meaning similar concepts cluster together in the vector space.
Step 3: Vector Storage & Indexing Vectors are stored in a specialised vector database Pinecone, Weaviate, Qdrant, or pgvector. Indexing strategies (HNSW, IVF) determine retrieval speed vs. accuracy trade-offs at scale.
Step 4: Semantic Retrieval When a user query arrives, it's embedded using the same model, then matched against stored vectors using approximate nearest-neighbour (ANN) search. Top-k results are retrieved and ranked by relevance score.
Step 5: Generation with Context Retrieved chunks are injected into the LLM's prompt as grounding context. The model generates a response strictly based on that retrieved information dramatically reducing hallucinations and improving factual accuracy.
Pro Tip Hybrid search combining dense vector retrieval with sparse BM25 keyword matching consistently outperforms either method alone. In our work with 50+ clients, hybrid RAG implementations showed a 23% improvement in answer relevance over pure vector search.
Real-World RAG Pipeline Case Study: Financial Services
A mid-size UK asset manager was spending 80 analyst-hours per week manually searching regulatory filings to answer compliance queries. We implemented a RAG pipeline implementation ingesting FCA circulars, internal policy documents, and client contracts over 2.3 million chunks indexed in Weaviate. After deployment, query response time dropped from 4 hours to 90 seconds, with a 94% accuracy rate validated against expert review. The team now uses data integration consulting services to keep the pipeline current as regulations evolve.
Complete RAG Pipeline Architecture Ingestion to Response
Vector Drift Monitoring: Keeping AI Answers Fresh
Here's a problem most teams discover too late: your RAG pipeline was accurate on day one. Six months later, it's returning outdated, misleading answers even though no one changed the code. This is vector drift, and it's one of the most underestimated risks in production AI systems.
What Causes Vector Drift?
Vector drift occurs when the semantic meaning of your stored embeddings diverges from the current language distribution of your users or your source documents. It happens because of three main forces:
Model updates: Your embedding model provider silently updates their model. Old vectors were generated with v1; new queries are embedded with v2. Cosine similarity scores become unreliable.
Data staleness: Source documents change products are deprecated, policies are updated but the vector index isn't refreshed.
Distributional shift: User query patterns evolve (new terminology, topics, use cases) while the index stays static.
How to Implement Vector Drift Monitoring
Monitoring Method | What It Detects | Tooling | Frequency |
Embedding Distribution Analysis | Model version drift, distributional shift | Evidently AI, WhyLabs, custom cosine stats | Daily |
Retrieval Quality Scoring | Relevance degradation over time | RAGAS, TruLens, DeepEval | Per-query sampling (5–10%) |
Source Document Freshness Audit | Stale knowledge base content | Custom timestamp tracking, dbt | Weekly |
In our experience, a 15% drop in mean retrieval cosine similarity is the reliable early-warning threshold for meaningful quality degradation. Setting automated alerts at this level gives engineering teams enough lead time to re-embed before users notice.
Context-Aware Memory Systems for LLMs
RAG gives your LLM long-term memory about your documents. But what about short-term, conversational memory the ability to maintain context across a multi-turn session? That's where context-aware memory systems come in.
The Four Memory Types Every LLM Stack Needs
Memory Type | Analogy | Use Case | Data Source | Example Tools |
|---|---|---|---|---|
In-context (short-term) | Working memory | Multi-turn chat, Q&A sessions | Live conversation input | LangChain Memory, OpenAI context window |
External (long-term) | Filing cabinet | User preferences, history | Databases (structured + unstructured) | PostgreSQL, Redis |
Episodic | Personal diary | Personalised AI agents | User interaction logs | MemGPT, Zep, Mem0 |
Semantic (RAG-backed) | Reference library | Domain knowledge grounding | Knowledge base / documents | Pinecone, Weaviate, Qdrant |
For enterprise deployments, combining episodic and semantic memory produces the most capable AI assistants. A customer service agent that remembers a client's prior complaints (episodic) while drawing on your latest product documentation (semantic RAG) delivers dramatically better resolution rates.
AI Data Readiness Assessment Framework
Before any RAG pipeline or memory system can succeed, you need an honest diagnosis of your starting point. Our AI data readiness assessment framework evaluates five dimensions each scored 1–5 to identify your highest-impact improvement areas.
The 5-Dimension Readiness Model
Dimension | Evaluation Criteria | Current Benchmark | Target Score | Business Impact |
|---|---|---|---|---|
Data Quality | Completeness, consistency, accuracy | 2.1 / 5 | 4+ / 5 | Reduces model hallucinations |
Data Accessibility | APIs, schema, contracts | 2.4 / 5 | 4+ / 5 | Faster AI deployment |
Infrastructure Scalability | Streaming, latency, vector readiness | 1.8 / 5 | 3.5+ / 5 | Enables real-time AI |
Governance & Compliance | PII handling, auditability | 2.7 / 5 | 4+ / 5 | Avoids regulatory risk |
Team Capability | ML + data + prompt engineering | 2.0 / 5 | 3.5+ / 5 | Sustains AI operations |
Based on industry research and our own AI transformation readiness assessments, the average enterprise scores 2.2 out of 5 across these dimensions before engaging a data engineering partner. Infrastructure scalability is almost always the lowest-scoring dimension and the biggest bottleneck to LLM deployment.
Key Takeaway An AI readiness assessment framework shouldn't just produce a score it should produce a prioritised roadmap. Score each dimension, identify the two biggest gaps, fix those first, and reassess quarterly.
FREE AI ASSESSMENT REPORT Not sure where your data gaps are? Get a personalised diagnosis of your AI data readiness no commitment required. Get Your Free AI Assessment Report →
Automated Data Labelling for LLMs
High-quality training and fine-tuning data is the foundation of every performant LLM. But manual data labelling is slow, expensive, and error-prone at scale. Automated data labelling for LLMs using LLMs themselves to generate, validate, and augment labels has emerged as the dominant approach in 2025–2026.
LLM-Assisted Labelling Workflows
The core idea behind data augmentation using LLMs is straightforward: use a capable foundation model (GPT-4o, Claude 3.5, Llama 3.1) to annotate your unlabelled dataset, then use a smaller subset of human-validated examples to calibrate and correct. This approach often called "LLM-as-annotator" can reduce labelling costs by 70–85% while maintaining accuracy within 3–5% of human annotators for most classification tasks [INSERT SOURCE: Scale AI 2025 Data Report].
Using LLMs for Data Analysis and Augmentation
Beyond labelling, LLMs for data analysis can identify patterns, generate synthetic training examples, and propose feature engineering strategies that human analysts would miss. For instance, when we worked with a large e-commerce client, using Claude to analyse 2M customer reviews produced 14 new sentiment dimensions that their manual taxonomy had completely overlooked directly improving their recommendation model's CTR by 18%.
Approach | Description | Cost (per 10K samples) | Accuracy | Speed / Scalability | Best Use Case |
|---|---|---|---|---|---|
Fully Manual | Human annotation only | $800–$2000 | 100% | Very slow, not scalable | Complex, high-risk tasks |
LLM-first + Human Review | AI labels + validation | $120–$280 | 95–97% | Fast with human bottleneck | Most enterprise use cases |
Fully Automated (LLM) | No human validation | $20–$60 | 88–93% | Extremely fast, highly scalable | Low-risk, large-scale tasks |
Active Learning + LLM | Iterative model improvement | $60–$150 | 96–98% | Optimised over time | Domain-specific datasets |
Data Governance for AI Compliance
An AI-ready data playbook without a governance layer is a liability, not an asset. As regulatory pressure intensifies EU AI Act enforcement began in August 2024, GDPR penalties continue to climb; governance is no longer optional for any organisation using AI on personal data.
The Four Pillars of AI Data Governance
Lineage & provenance tracking: Every data record used in model training or RAG retrieval must be traceable to its origin. Tools: Apache Atlas, OpenMetadata, DataHub.
PII detection & masking: Automated scanning for personally identifiable information before data enters any LLM pipeline. Tools: Microsoft Presidio, AWS Comprehend, Scrubadub.
Access control & audit logging: Role-based access to vector indices and model endpoints, with immutable audit trails. Tools: OPA (Open Policy Agent), AWS Lake Formation, Databricks Unity Catalog.
Model card & documentation standards: Every deployed model must have documented training data sources, known limitations, evaluation metrics, and intended use cases.
Our comparison of leading AI governance platforms shows that organisations using mature governance frameworks deploy AI initiatives 2.3× faster than those without because approval cycles shrink when compliance teams have visibility and control.
For a deeper look at how governance evolves with organisational maturity, see our guide on AI governance maturity models. And if you need help with security implementation, our AI security and compliance services cover the full spectrum from policy to technical controls.
Pro Tip Implement a "data passport" system a metadata record attached to every dataset entering your AI stack. It should contain: source, collection date, PII status, consent basis, approved use cases, and expiry date. This single practice eliminates the majority of governance audit failures.
Essential Tools & Technology Stack
Choosing the right tooling is half the battle. Here's the reference stack we recommend for organisations building their first or second AI-ready data pipeline, based on our experience at the intersection of AI and data engineering.
Layer | Open Source Options | Managed Tools | Recommended Pick (2026) | Primary Use Case | Key Advantage |
|---|---|---|---|---|---|
Orchestration | Airflow, Prefect | Astronomer, Databricks | Prefect | Workflow automation | Easy setup, developer-friendly |
Embeddings | BGE-M3, Nomic | OpenAI, Cohere | Cohere | Semantic encoding | Strong multilingual performance |
Vector DB | Qdrant, Weaviate | Pinecone, Zilliz | Qdrant | Similarity search | High performance + cost efficiency |
RAG Framework | LangChain, LlamaIndex | Bedrock KB | LlamaIndex | Retrieval pipelines | Enterprise-ready abstractions |
Drift Monitoring | Evidently AI | WhyLabs, Arize | Evidently + RAGAS | Model quality tracking | Open-source + flexible |
Data Quality | Great Expectations | Monte Carlo | GE + dbt | Data validation | Strong testing ecosystem |
Governance | OpenMetadata | Collibra, Alation | OpenMetadata | Compliance & lineage | Cost-effective governance |
REQUEST A FREE PRODUCT DEMO See the full stack in action our team walks you through a live implementation of the AI-ready data playbook on your own use case. Request a Free Product Demo →
Future Trends: 2026–2030
The AI data landscape is moving fast. Here are the five trends that will define AI-ready data engineering over the next four years, based on trajectory analysis and our conversations with leading practitioners.
1. Agentic Data Pipelines
AI agents that autonomously monitor data quality, trigger re-indexing when drift is detected, and resolve schema conflicts without human intervention are moving from prototype to production. Expect this to be the default for mature data platforms by 2027.
2. Multimodal RAG
Current RAG systems are predominantly text-based. By 2028, the mainstream implementation will natively handle text, images, audio transcripts, structured tables, and video enabling AI systems that reason across data types simultaneously.
3. Federated AI Data Systems
Regulatory pressure and data sovereignty requirements will drive adoption of federated architectures where models are trained or fine-tuned on local data without centralising sensitive records. Continuous improvement in AI will depend on these privacy-preserving techniques.
4. AutoML for Data Pipeline Optimisation
AutoML tools will expand beyond model selection into pipeline configuration automatically tuning chunking strategies, retrieval parameters, and embedding model selection based on domain-specific benchmarks.Google Research AutoML documentation
5. Quantum-Accelerated Vector Search
Though still early-stage, quantum annealing processors are showing promise for approximate nearest-neighbour search at scales that overwhelm current HNSW implementations. By 2030, quantum-classical hybrid vector search may be commercially viable for the largest AI platforms. IBM Quantum research on vector optimisation
Conclusion
Building an AI-ready data playbook is the most leveraged investment your organisation can make right now. Every AI initiative whether it's a customer-facing LLM assistant, an internal knowledge retrieval system, or a predictive analytics model runs better, faster, and with fewer hallucinations when the data layer is architected for AI from the ground up. The six pillars we've covered RAG pipeline architecture, vector drift monitoring, context-aware memory systems, AI data readiness assessment, automated data labelling, and governance aren't independent projects. They're interconnected layers of a single system. Get all six right and you have a compounding advantage: each AI initiative builds on a stronger foundation than the last. Start with your readiness assessment. Identify your two highest-impact gaps. Fix those. Then revisit samta.ai when you're ready to move to the next layer.
Not sure if your data infrastructure is truly AI-ready? Contact our experts to assess your data pipelines, governance framework, and integration gaps.
About Samta
Samta.ai is an AI Product Engineering & Governance partner for enterprises building production-grade AI in regulated environments.
We help organizations move beyond PoCs by engineering explainable, audit-ready, and compliance-by-design AI systems from data to deployment.
Our enterprise AI products power real-world decision systems:
TATVA : AI-driven data intelligence for governed analytics and insights
VEDA : Explainable, audit-ready AI decisioning built for regulated use cases
Property Management AI : Predictive intelligence for real-estate pricing and portfolio decisions
Trusted across FinTech, BFSI, and enterprise AI, Samta.ai embeds AI governance, data privacy, and automated-decision compliance directly into the AI lifecycle, so teams scale AI without regulatory friction.
Enterprises using Samta.ai automate 65%+ of repetitive data and decision workflows while retaining full transparency and control.
Samta.ai provides the strategic consulting and technical engineering needed to align your human capital with your AI goals, ensuring a frictionless.
Frequently Asked Questions
What's the difference between a RAG pipeline and traditional search?
Traditional search returns documents ranked by keyword relevance. A RAG pipeline goes further: it retrieves semantically relevant chunks, feeds them as grounding context to an LLM, and generates a synthesised natural-language answer. Traditional search gives you documents to read; RAG gives you answers grounded in those documents. For enterprise knowledge management, this distinction translates to a 60–80% reduction in time-to-answer for complex queries.
How long does it take to implement an AI-ready data pipeline?
A basic RAG pipeline implementation on an existing data source typically takes 4–8 weeks for a competent team with clean data. Add 4–6 weeks if significant data cleaning is needed. A full AI-ready data stack with drift monitoring, governance, and automated labelling — is realistically a 4–6 month initiative for a mid-size organisation. The fastest deployments we've seen use data integration consulting services to accelerate the ingestion and normalisation phases.
What is an AI data readiness assessment and how is it conducted?
An AI data readiness assessment is a structured audit of your data estate against the requirements of AI/LLM workloads. It covers data quality, accessibility, governance maturity, infrastructure scalability, and team capability each scored against a defined benchmark. The assessment produces a gap analysis and a prioritised remediation roadmap. A basic self-assessment can be completed using our AI readiness checklist; a comprehensive third-party assessment typically takes 2–4 weeks and includes data profiling, pipeline architecture review, and interviews with data owners.
What compliance standards apply to AI data pipelines in 2026?
The regulatory landscape has become complex. In the EU, the AI Act (in enforcement since August 2024) classifies many LLM deployments as high-risk systems subject to conformity assessments, data governance requirements, and human oversight mandates. The GDPR applies whenever personal data enters your pipeline including via RAG retrieval. In the UK, the ICO has published specific guidance on AI and data protection. In the US, sectoral regulations (HIPAA, FCRA, CCPA) create a patchwork of requirements. Our AI security and compliance services map your specific stack to the applicable regulations.
What skills does our team need to implement an AI-ready data stack?
A complete implementation team needs: data engineers (pipeline design, vector DB management, streaming infrastructure), ML engineers (embedding model selection, RAG optimisation, fine-tuning), data governance specialists (lineage tracking, compliance), and prompt engineers / LLM product managers (query interface design, evaluation). Most mid-size organisations accelerate significantly by partnering with a specialist firm rather than hiring all these roles in-house. See our resources oncontinuous improvement in AI teams for org design guidance.