
Summarize this post with AI
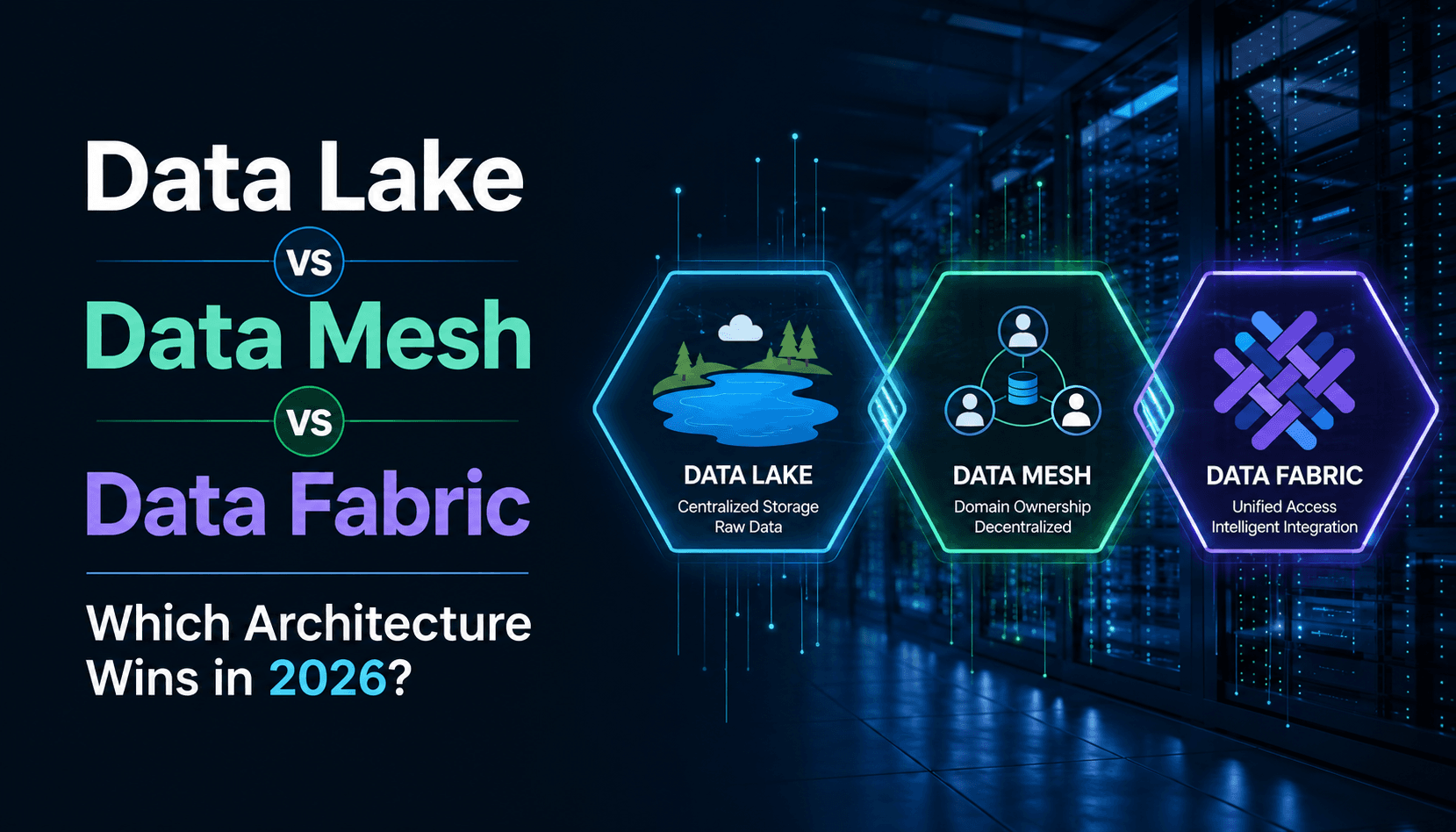
Modern enterprises often struggle to choose between a data lake vs data mesh vs data fabric when scaling their analytical capabilities. While a data lake offers centralized storage, data mesh trends and architectures emphasize decentralized domain ownership to prevent operational bottlenecks. Conversely, a data fabric acts as an intelligent abstraction layer, automating integration across disparate and siloed sources. Understanding the nuances of data fabric vs data warehouse models is essential for optimizing real-time business intelligence and ensuring model accuracy. This advisory brief evaluates these frameworks to help IT leaders move beyond legacy silos. By aligning infrastructure with specific business goals, organizations can ensure high-quality data availability for AI initiatives while maintaining rigorous governance.
Why This Comparison Matters Now
As AI adoption accelerates, choosing between data lake vs data mesh vs data fabric directly impacts how fast your organization can operationalize insights. Traditional systems struggle with fragmented pipelines, while modern architectures must support real-time intelligence, multi-cloud environments, and scalable governance.
For example, what is a data fabric architecture? It is a metadata-driven design that creates a unified data layer across distributed systems without physically consolidating everything. According to Gartner’s research on data fabric, this approach significantly reduces integration complexity and accelerates data access.
Organizations building robust Enterprise AI Data Infrastructure increasingly combine these frameworks to eliminate silos and improve decision velocity. This is especially critical when aligning with strategies like Building an AI-Ready organization, where data accessibility directly drives AI outcomes.
Key Takeaways
Data lakes provide scalable storage but often lack governance if unmanaged
Data fabric uses active metadata to automate integration and orchestration
Data mesh shifts ownership to domain teams, enabling agility
Culture and operating model matter as much as technology
Hybrid models dominate modern AI-Ready Data Engineering strategies
What This Means in 2026
The debate around data lake vs data mesh vs data fabric is no longer purely architectural it’s strategic. Enterprises must balance data sovereignty, accessibility, and speed.
Data lakes remain foundational for storing large-scale, unstructured data
Data mesh trends and architectures emphasize autonomy and scalability
Data fabric acts as the connective intelligence layer across ecosystems
To support this, organizations are investing in Enterprise AI Data Infrastructure that integrates cloud, on-premise, and edge environments seamlessly.
Benchmark your data maturity and discover the best architecture for your needs.
Claim your Free AI Assessment Report to unlock actionable technical insights.
Core Comparison: Architectural Frameworks
Choosing between data lake vs data mesh vs data fabric requires understanding how each model handles ownership, integration, and scale:
Framework | Primary Objective | Ownership Model | Best For | Governance & Integration Style |
Data Lake | Centralized raw storage | Centralized IT | Large-scale unstructured data | Limited native governance; requires external tools for metadata and control |
Data Fabric | Automated orchestration | Centralized/Automated | Siloed, hybrid environments | Metadata-driven governance with automated integration across distributed systems |
Data Mesh | Domain-driven data products | Decentralized domains | Complex, global organizations | Federated governance with domain-level ownership and standardized policies |
Data Warehouse | Structured reporting | Centralized IT | BI and SQL analytics | Strong schema-based governance with tightly controlled, structured data pipelines |
This comparison also clarifies data fabric vs data warehouse differences where warehouses store structured data, fabrics connect distributed systems intelligently.
How to Apply These Frameworks
1. Decentralized Product Development
Use data mesh trends and architectures to empower business units to own and manage their data as products.
2. Automated Data Discovery
Leverage fabric architectures to accelerate Data Discovery for AI across distributed systems.
3. Legacy Modernization
Enhance existing ecosystems through Enterprise Data Integration Engineering, layering fabric capabilities over legacy warehouses.
4. Unified Intelligence
Use data lakes for ingesting IoT, logs, and high-volume datasets feeding AI models.
5. Regulatory Compliance
Define clear ownership boundaries (mesh) and lineage tracking (fabric) for regulated industries.
Limitations & Risks
A Data mesh vs data fabric architecture vs data warehouse analysis reveals practical challenges:
Data mesh requires strong organizational maturity and governance discipline
Data fabric can be complex to implement without the right metadata strategy
Data lakes risk becoming “data swamps” without proper controls
High upfront investment and talent gaps can delay ROI
Without a strong hiring strategy especially around modern data roles initiatives often fail to scale effectively.
Decision Framework: Which Should You Choose?
Choose Data Mesh if your organization is domain-driven and needs independent scalability
Choose Data Fabric if your priority is integrating siloed systems without migration
Choose Data Lake if you need cost-effective, large-scale storage
In reality, leading enterprises combine all three. Platforms like VEDA AI Data Analytics Platform help unify these architectures, enabling visibility, governance, and scalability from a single layer. For tailored implementation, Data Integration Consulting Services can align architecture decisions with long-term AI strategy and ROI.
See how our VEDA platform and integration services can unify your data silos.
Request a Free Product Demo with Samta.ai and start your modernization journey.
Conclusion
Choosing between data lake vs data mesh vs data fabric is not about picking a single winner it’s about designing a system that matches your business reality. Data lakes provide scale, data mesh enables ownership, and data fabric delivers integration. The most successful organizations in 2026 adopt a hybrid, AI-first architecture that blends these approaches. By combining strategic design with the right tools and expertise, enterprises can unlock faster insights, stronger governance, and sustainable AI growth. Explore more about building future-ready systems at Samta.ai.
Streamline your enterprise data architecture for the AI era.
Contact us today to consult with our expert data engineers.
About Samta
Samta.ai is an AI Product Engineering & Governance partner for enterprises building production-grade AI in regulated environments.
We help organizations move beyond PoCs by engineering explainable, audit-ready, and compliance-by-design AI systems from data to deployment.
Our enterprise AI products power real-world decision systems:
TATVA : AI-driven data intelligence for governed analytics and insights
VEDA : Explainable, audit-ready AI decisioning built for regulated use cases
Property Management AI : Predictive intelligence for real-estate pricing and portfolio decisions
Trusted across FinTech, BFSI, and enterprise AI, Samta.ai embeds AI governance, data privacy, and automated-decision compliance directly into the AI lifecycle, so teams scale AI without regulatory friction.
Enterprises using Samta.ai automate 65%+ of repetitive data and decision workflows while retaining full transparency and control.
Samta.ai provides the strategic consulting and technical engineering needed to align your human capital with your AI goals, ensuring a frictionless.
Frequently Asked Questions (FAQs)
What is the main difference in a data lake vs data mesh vs data fabric?
A Data Lake is centralized storage, Data Mesh is a decentralized ownership model, and Data Fabric is a unifying integration layer. Most enterprises use a combination for scalability.
How does a data fabric differ from a traditional warehouse?
This highlights data fabric vs data warehouse differences: warehouses store structured data centrally, while fabrics connect and orchestrate data across systems using metadata.
Is Data Mesh better than Data Fabric for AI?
It depends. Data mesh works best for decentralized teams, while data fabric is ideal for automating Data Discovery for AI across complex environments.
Can you use a Data Lake with a Data Mesh?
Yes. Domains within a mesh can operate their own lakes and expose curated “data products” to the organization.