

Summarize this post with AI
72 percent of AI investments are destroying value through waste, and only 29 percent of organizations can measure ROI confidently despite 79 percent reporting productivity gains. The gap is not the AI model and it is not the engineering team. It is the absence of a measurement framework built before deployment, not assembled after a board asks where the returns are. AI engineering ROI is not a build problem; it is a permanent operations and measurement problem that compounds with every user you add. This guide gives CTOs and engineering leaders a four-pillar ai engineering roi framework for measuring value before scaling, so the business case survives a CFO review rather than collapsing at one.
AI Engineering ROI:
AI engineering ROI is the measurable business value generated from deploying AI systems relative to the full cost of building, running, and maintaining them across four pillars: cost efficiency, performance, delivery efficiency, and business impact. Only 41 percent of agent rollouts cross positive ROI within 12 months and 19 percent never reach payback, per Gartner 2026, making pre-deployment measurement design the single most consequential decision in any AI engineering program. McKinsey's five-layer AI measurement framework establishes that credible ROI requires a pre-registered hypothesis, a baseline of the workflow being changed, and a control mechanism before a single line of code is written not retrospective attribution after the fact.
What AI Engineering ROI Actually Measures
roi of ai engineering projects is not the same as general AI ROI. It is specifically the return generated by the engineering investment: the data pipelines, model integrations, MLOps infrastructure, evaluation harnesses, and the ongoing cost of running, monitoring, and updating those systems in production. The formula is deceptively simple: ROI equals total business value minus total cost, divided by total cost. Applying it honestly to AI engineering requires accounting for seven cost categories that most business cases miss: build cost, inference at projected scale, integration and engineering work to wire AI into existing systems, evaluation and observability infrastructure, governance and compliance cost (rising fast in 2026 as MAS AIRG, EU AI Act, and US sectoral rules add review cycles to every production change), change management and training, and ongoing maintenance including drift management and version migrations as model vendors release new generations.
The most common error is building a cost model around the proof of concept and scaling it linearly. Inference costs at production scale bear no linear relationship to pilot costs, particularly for agentic workflows running continuous loops. For enterprises assessing their overall analytics investment before this measurement exercise, the enterprise AI analytics 2026 guide and the AI readiness assessment for CTOs provide the baseline context this framework assumes.
Why Measurement Frameworks Matter More Than Models in 2026
Three developments make pre-deployment measuring ai engineering value more consequential than choosing the right model.
1. Boards have moved from adoption metrics to P&L proof: Direct financial impact, combining revenue growth and profitability, nearly doubled to 21.7 percent as the primary ROI metric in 2026, per Futurum Group's survey of 830 IT decision-makers. Simultaneously, productivity gains collapsed 5.8 percentage points as the leading success measure. The board conversation that worked in 2024, showing hours saved per week, no longer carries the CFO review in 2026.
2. The missing baseline problem is creating systemic ROI failure: The single most common failure point is the missing baseline: without pre-AI measurements of the processes AI will affect, every ROI claim is anecdotal. 70 percent of organizations discover data infrastructure gaps only after launching, and without a baseline, those gaps become the reason measurement fails, not the AI itself.
3. Inference cost surprises are the most common reason scaled programs miss targets: An AI tool that costs $2,000 per month in pilot can require $40,000 per month at full production. The LCOAI Curve, which compares cost per inference between cloud API and self-hosted deployments, is a measurement dimension most organizations overlook entirely when calculating operational ROI. Understanding how ai in engineering projects connects to business outcomes is the prerequisite to any scaling decision. The AI governance in business context guide covers how governance cost itself factors into the measurement model, and the AI transformation roadmap template provides the sequencing framework this measurement approach fits within.
Get your pre-deployment baseline assessment completed before committing any engineering budget to scale. Request a Free AI Assessment Report from Samta.ai and enter scale decisions with verified measurement inputs rather than pilot extrapolations.
The AI Engineering ROI Framework: Four Pillars Before You Scale
Use this structure to instrument your ai engineering roi measurement before a single production line deploys.
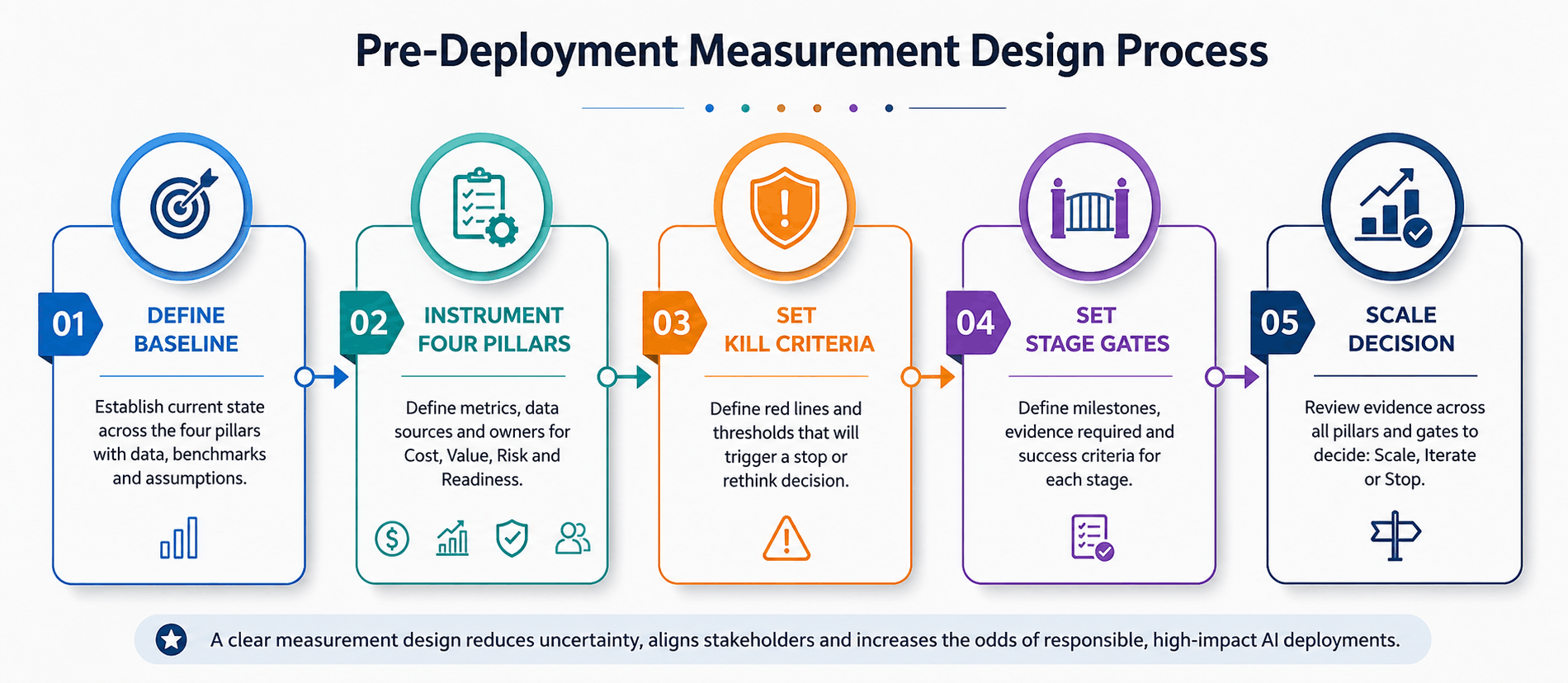
Pillar 1: Cost Efficiency
Cost per inference: measure at pilot volume and at 5x, 10x, and 50x projected production scale before committing to deployment. The unit economics at scale are the only ones that matter for a scaling decision.
Infrastructure utilization: GPU and compute utilization against provisioned capacity; underutilization is a cost efficiency failure that does not appear in productivity metrics.
Model update cost: time to model update is the metric that rarely appears in ROI models but should. Because foundational models improve and are superseded on a cycle of months, the competitive value of any AI product degrades continuously unless the architecture allows rapid model substitution.
Pillar 2: Performance
Latency and throughput: establish production-grade SLA targets before deployment, not after user complaints surface.
Accuracy on the golden set: a pre-committed accuracy floor (for example, accuracy on the golden set below 85 percent at day 30 triggers a model or retrieval change) is a kill criterion that separates disciplined programs from those that keep spending against failing pilots.
Hallucination and error rate: AI systems that hallucinate in customer-facing interactions create measurable liability and reputation damage, both of which carry direct financial consequences in regulated industries.
Pillar 3: Delivery Efficiency
Delivery efficiency has the clearest near-term measurement evidence and the fastest payback timeline. Vendor-deployed agents reach positive ROI 2.4 times faster than internally built custom agents, per Bain Agentic AI Benchmark 2026, because they ship with evaluation harnesses and integration templates that custom builds had to invent. The key metrics are deployment frequency, AI adoption by software development lifecycle phase, and scope per engineer before and after AI tooling is introduced.
Delivery efficiency gains become visible within 60 to 90 days of full toolchain adoption. Business impact metrics require 90 to 180 days and proper instrumentation from deployment day one.
Pillar 4: Business Impact
This is the pillar the CFO cares about and the one most AI engineering programs are weakest at measuring. Productivity value becomes defensible only when it converts into one of four downstream effects: headcount neutrality against rising volume where you absorb growth without hiring; service-level improvements that protect renewal revenue or reduce churn; capacity redirection to revenue-generating work with the revenue tracked back; or reduced overtime, contractor spend, or outsourced processing.
Without one of these conversions, saved hours do not appear at the P&L line, and the productivity number stops counting. Samta.ai's Veda AI decision analytics platform supports this pillar by connecting AI model outputs directly to business outcome dashboards, so measuring ai engineering value across all four pillars is a live operational capability rather than a quarterly estimate. The Veda AI decision analytics platform integrates with cloud data platforms including Databricks and Snowflake, and pairs with Samta.ai's data integration consulting services for enterprises that need the measurement infrastructure built alongside the model.
For documented examples of how this framework has been applied in production, see Samta.ai's case studies.
AI Engineering ROI Measurement: Benchmarks by Use Case
Use Case | Delivery Efficiency Payback | Business Impact Payback | Primary Cost Driver | Kill Criterion | Governance Complexity |
Customer service AI agents | 30 to 60 days | 4.1 months median (Bain 2026) | Inference cost per resolved ticket ($0.46 vs $4.18 human) | Adoption floor below 50% at day 60 triggers review | Low, standard audit trail |
Engineering and code review | 60 to 90 days | 9.3 months median (Bain 2026) | Evaluation infrastructure, 2x higher for custom builds | Accuracy on golden set below 85% at day 30 | Low to moderate |
Finance and compliance automation | 60 to 90 days | 8 months median (Sinequa 2026) | Governance and compliance cost rising fastest in 2026 | Unit economic ceiling per resolved transaction | High, audit trail and explainability required |
Credit and fraud detection (BFSI) | 90 to 180 days | 12 to 18 months | Data pipeline and entity resolution, lineage documentation | Accuracy floor plus regulatory audit trail completeness | Very high, MAS and sector documentation required |
Marketing operations automation | 30 to 60 days | 6.7 months median (Bain 2026) | Campaign data integration, CRM pipeline costs | Revenue per campaign against pre-AI baseline | Low to moderate |
Enterprise Use Cases: Measuring AI Engineering ROI in Practice
Use Case 1: Singapore Bank Instrumenting Credit AI for MAS Review
A Singapore bank's engineering team deployed credit decisioning AI and built the measurement layer before production launch: a documented baseline of manual review time, accuracy rate on a golden set of historical decisions, cost per decision at three volume tiers, and an audit trail connecting every model output to the business outcome it influenced. When MAS examiners requested governance documentation, the bank produced a measurement record that covered all four pillars, not just model accuracy. The AI ROI for customer-facing AI guide covers how this measurement structure applies across customer-facing financial services deployments more broadly. The combination of pre-committed kill criteria and continuous monitoring meant the bank could demonstrate to its board that ROI was tracked from day one, not reconstructed after the fact.
Use Case 2: Technology Enterprise Proving Delivery ROI Within 90 Days
A Singapore technology company deployed an AI code review agent and committed to measuring delivery efficiency before business impact, using deployment frequency and scope per engineer as the primary 90-day metrics. Within 60 days, deployment frequency increased 34 percent and defect cost avoided per sprint was measurable against a documented baseline. At the 90-day gate, the business impact pillar was still developing, consistent with the 90 to 180 day timeline for business impact metrics to emerge. The team used the 90-day delivery evidence to secure continued investment without needing the full P&L impact to be visible yet, demonstrating how a phased measurement approach sustains board confidence through the full maturation cycle.
Key Risks and Failure Modes
No baseline before deployment: Without pre-AI measurements of the workflows AI will affect, every ROI claim is anecdotal. Baselines must be documented before the first line of production code is written, not estimated retrospectively when a board asks for evidence.
Single-pillar measurement: A number built on one or two pillars, typically delivery efficiency or productivity, is easy to challenge. A number built on all four pillars is a business case. Programs that measure only hours saved collapse under CFO scrutiny because saved hours that do not convert to P&L outcomes do not count.
Missing kill criteria: Pre-committed kill criteria, an adoption floor, an accuracy floor, and a unit economic ceiling, are how disciplined enterprises stop spending against pilots that go nowhere. They are also how a CTO maintains credibility with the CFO across multiple investment cycles.
Confusing pilot cost with production cost: The most common cost modeling error is building a unit cost estimate from the proof of concept and scaling it linearly. Inference costs at scale, governance overhead, and model update costs all scale non-linearly and must be modeled at 5x and 10x pilot volume before any scaling decision is made.
AI Model Risk Exposure Scorecard Quantify the measurement gaps and cost exposure sitting inside your current AI engineering program before your next scaling decision. Request the AI Model Risk Exposure Scorecard from Samta.ai and connect your risk posture directly to your ROI measurement framework.
Decision Framework: Is Your AI Engineering Program Ready to Scale?
A pre-deployment baseline exists for every metric the business case claims will improve
Cost per inference has been modeled at 5x and 10x current volume, not just pilot volume
All four measurement pillars are instrumented: cost efficiency, performance, delivery efficiency, and business impact
Pre-committed kill criteria (adoption floor, accuracy floor, unit economic ceiling) are documented and agreed with leadership
Governance and compliance cost is included in the total cost of ownership model
A measurement cadence with explicit stage gates is scheduled before scaling begins
If fewer than four boxes are checked, the program is not yet ready to scale and additional investment will compound the measurement gap rather than resolve it.
Conclusion
ai engineering roi measurement is not a post-deployment exercise. It is a pre-deployment design decision that determines whether scaling a project delivers a defensible business case or compounds a measurement gap into a budget credibility problem. With only 29 percent of organizations able to measure ROI confidently despite 79 percent reporting productivity gains, the measurement framework is now the primary differentiator between AI programs that secure continued investment and those that face budget cuts at the next board review.
Get the complete measurement framework template: four-pillar instrumentation design, baseline documentation structure, kill criteria template, and stage-gate cadence in one document. Request the AI Implementation Playbook from Samta.ai and build a measurement layer that survives CFO scrutiny before you commit to scale.

About Samta
Samta.ai is a Singapore-headquartered AI Product Engineering & Data Intelligence partner helping enterprises build production-grade AI systems for regulated and data-intensive environments.We help organizations move beyond experimentation by engineering scalable, explainable, and enterprise-ready AI solutions from data foundations and model development to workflow automation and deployment.
Our capabilities combine deep AI expertise, data engineering, and product engineering to deliver measurable business impact across FinTech, BFSI, cybersecurity, regulatory technology, and enterprise operations.
Our enterprise AI products power real-world intelligence systems:
• TATVA : AI-driven data intelligence platform for governed analytics, monitoring, and operational insights
• VEDA : Explainable and audit-ready AI decisioning engine built for compliance-sensitive enterprise workflows
• CORA-Property Management Solutions: : Predictive intelligence platform for real-estate pricing, portfolio optimization, and investment analytics
Backed by ecosystem partnerships with Microsoft, Databricks, Snowflake, and AWS, Samta.ai delivers agile, cost-efficient AI engineering with faster turnaround and enterprise-grade scalability. Trusted by enterprises across FinTech, BFSI, and digital transformation initiatives, Samta.ai embeds AI governance, data privacy, and compliance-by-design principles directly into the AI lifecycle , enabling organizations to scale AI with transparency, accountability, and operational control.
Enterprises leveraging Samta.ai automate 65%+ of repetitive data, analytics, and decision workflows while maintaining governance, explainability, and measurable business outcomes. Samta.ai provides the strategic consulting, AI engineering, and data modernization expertise needed to align enterprise operations with next-generation AI transformation goals.
Frequently Asked Questions
What is AI engineering ROI and how is it different from general AI ROI?
AI engineering roi specifically measures the return generated by the engineering investment: data pipelines, model integrations, MLOps infrastructure, evaluation harnesses, and the ongoing cost of running and maintaining AI systems in production. General AI ROI measures broader organizational impact. AI engineering ROI requires accounting for seven cost categories including inference at scale, governance cost, and model update cost that general AI ROI frameworks routinely omit.
What are the four pillars of measuring AI engineering value?
measuring ai engineering value requires four pillars measured simultaneously: cost efficiency, covering cost per inference and infrastructure utilization; performance, covering latency, accuracy, and error rates; delivery efficiency, covering deployment frequency and scope per engineer; and business impact, covering P&L-connected outcomes including cost reduction, revenue attribution, and headcount neutrality. A business case built on all four pillars survives board scrutiny; one built on one or two does not.
How long does it take for AI engineering ROI to become measurable?
Delivery efficiency gains become visible within 60 to 90 days of full toolchain adoption. Infrastructure and cost efficiency gains become visible within 60 to 90 days. Business impact metrics require 90 to 180 days and proper instrumentation from deployment day one. Finance use cases show the fastest payback at approximately 8 months; BFSI credit and fraud detection use cases typically run 12 to 18 months to measurable business impact ROI.
How do you measure how to measure ai efficiency for agentic systems specifically?
For agentic AI, traditional throughput and latency metrics are necessary but not sufficient. The key additional metric is time to model update, which measures how quickly the architecture can swap foundational models as new generations release. Model lock-in is not just a vendor risk; it is a financial one, because switching foundational models requires reworking prompt logic, output validation, and downstream processes. Agentic systems also require continuous cost monitoring because inference costs scale non-linearly with loop-based autonomous workflows.
What is the biggest mistake enterprises make when measuring AI engineering ROI?
The single most consistent failure point is the missing baseline problem. Without pre-AI measurements of the workflows AI will affect, every ROI claim is anecdotal and fails under CFO scrutiny. The second most common mistake is building a cost model from the proof of concept and scaling it linearly inference costs, governance overhead, and model update costs all scale non-linearly and must be explicitly modeled at production volume before any scaling decision is made.