

Summarize this post with AI
Most enterprises hire data scientists first and wonder eighteen months later why nothing has reached production. The right AI engineering team structure is not a headcount problem it is a sequencing problem, and getting the order of roles wrong is the single most common reason AI initiatives stall between pilot and deployment. This guide breaks down exactly which roles a production-ready AI engineering team structure requires, in what order to hire them, and how reporting lines should be designed for enterprise and BFSI organisations operating under regulatory scrutiny in 2026.
AI Engineering Team Structure
A production-ready AI engineering team structure requires five core role categories working in sequence: data engineers and platform engineers to build the foundation, ML engineers and data scientists to develop models, MLOps engineers to deploy and monitor them, an AI/model risk lead to embed governance, and a product owner to tie outputs to business value. For BFSI and regulated enterprises, the AI/model risk lead role is non-negotiable and should be staffed before the first model reaches production not after a regulator asks for documentation.
What an AI Engineering Team Structure Actually Means
AI team roles are frequently confused with general software engineering roles, but AI development introduces dependencies that standard product teams do not have. An effective AI engineering team is not a flat collection of data scientists it is a layered structure where each role depends on the output of the one before it.
The core role categories are:
Data engineers: build and maintain ingestion pipelines, data quality, and warehousing infrastructure
ML engineers / data scientists: develop, train, and validate models against business and statistical benchmarks
MLOps engineers: deploy, monitor, and maintain models in production, including drift detection and retraining pipelines
AI/model risk lead: owns governance, explainability, audit trails, and regulatory alignment
AI product owner: translates business problems into scoped use cases and owns the value delivered
Compared to a typical agile engineering team structure, AI teams require an additional governance layer and a data foundation layer that standard product squads do not need — which is precisely why copying a generic engineering org chart for AI hiring consistently underperforms. Use a structured AI readiness assessment to determine which of these layers your organisation already has versus which require new hires.
Why Team Structure Matters More in 2026
Three forces have changed how hiring for AI engineering should be sequenced:
1. Governance is now a staffing requirement, not a policy document
NIST's AI Risk Management Framework and MAS Technology Risk Management guidelines increasingly expect organisations to demonstrate accountable ownership of model risk — not just a written policy. A documented AI risk and compliance framework requires a named owner, which means the AI/model risk lead role must exist before production deployment, not be assigned informally to a data scientist as a side responsibility.
2. The data engineering bottleneck is now well understood
Enterprises that hire ML engineers before data engineers consistently stall, because there is no governed data pipeline to build models against. Sequencing data engineering first is now standard practice among mature AI organisations, not an optional best practice.
3. AI is being used in hiring itself
The irony is notable: organisations are now using AI in hiring to identify and assess the very AI engineering talent they need to hire. Structured, role-specific assessment rather than generic technical screening has become essential given how scarce and expensive senior AI engineering talent has become across APAC.
Free AI Assessment Report Get a clear picture of which AI engineering roles your organisation already has covered and which gaps are blocking production. Request your complimentary assessment →
The 5-Step Framework for Building an AI Engineering Team Structure
Use this sequence when building or restructuring an AI engineering function:
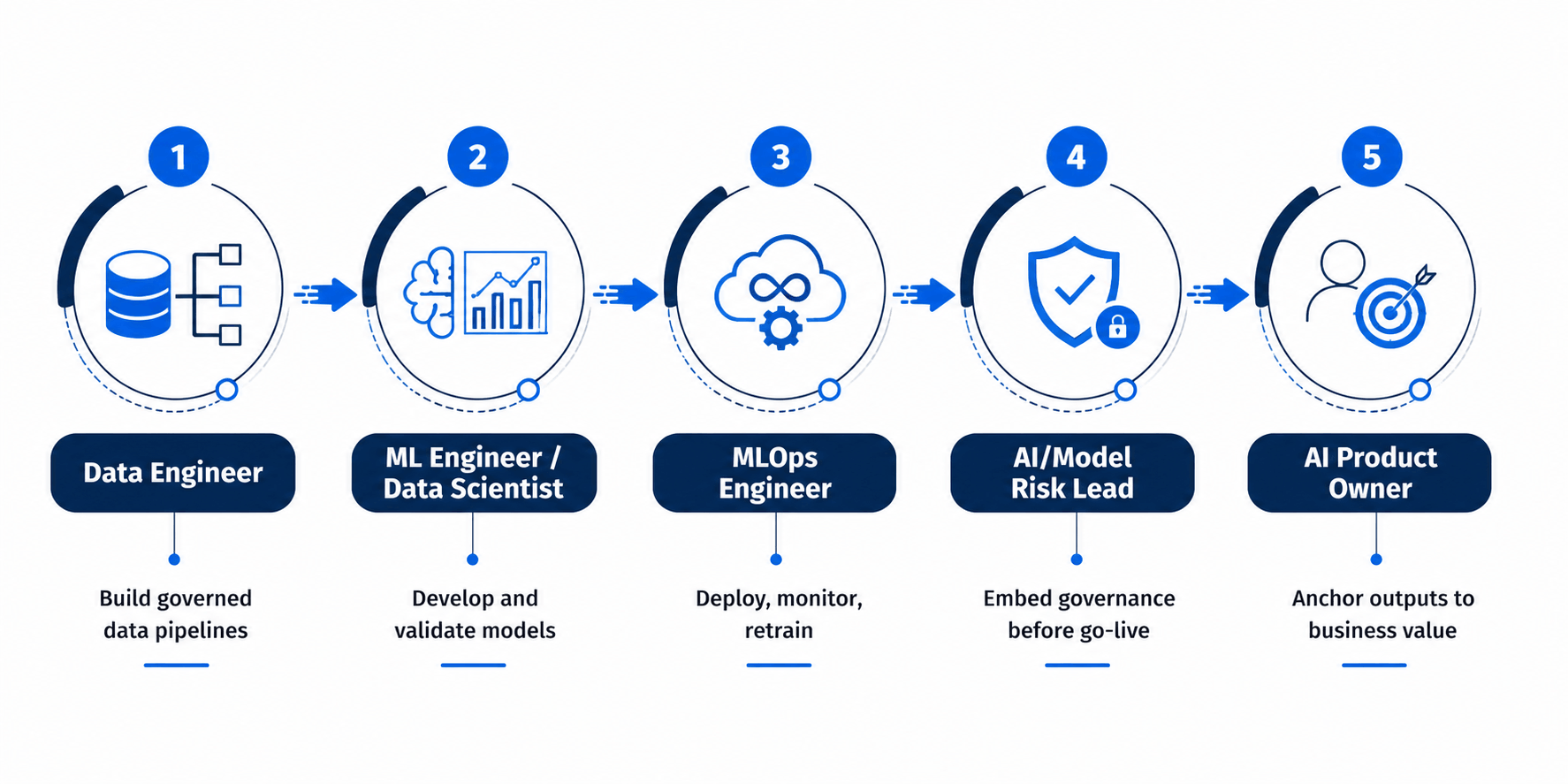
Step 1: Establish the Data Foundation First
Hire or assign data engineers before any ML engineering role. Their mandate: build governed, queryable pipelines on platforms such as Snowflake, Databricks, or Microsoft Azure. No model development should begin until a baseline data foundation exists.
Step 2: Bring In ML Engineers and Data Scientists Together
These two roles are complementary, not interchangeable. Data scientists focus on model selection, feature engineering, and statistical validation; ML engineers focus on making those models scalable, reproducible, and production-ready. Hiring only one of the two creates a structural gap either models that never leave a notebook, or production infrastructure with no model logic worth deploying.
Step 3: Staff MLOps Before Your First Production Deployment
MLOps engineers own CI/CD pipelines, containerisation, monitoring, and retraining automation. Without this role, every model deployment becomes a manual, high-risk event rather than a repeatable process. This is also where Samta.ai's digital transformation managed services function as the engineering execution layer embedding MLOps tooling and monitoring infrastructure directly into the deployment pipeline rather than treating it as a separate workstream.
Step 4: Name an AI/Model Risk Lead Before Go-Live
This role owns model cards, audit trails, explainability reporting, and regulatory alignment. For BFSI organisations, this is the role most often missing from early-stage AI teams and the one regulators ask about first. Samta.ai's AI security and compliance services support this function directly when internal capability is still being built.
Step 5: Appoint an AI Product Owner to Anchor Business Value
Without a product owner accountable for tying model outputs to a defined business outcome, AI teams default to optimising technical metrics that do not translate into measurable value. This role should report into the business function the AI use case serves not exclusively into engineering.
AI Engineering Team Structure: 5-Column Role Comparison
Role | Core Responsibility | Typical Reporting Line | When to Hire (Sequence) | Risk if Missing |
Data Engineer | Build and maintain governed data pipelines | Head of Data / CTO | First: before any ML role | No usable data foundation; ML work stalls indefinitely |
ML Engineer / Data Scientist | Develop, train, validate models | Head of AI / Engineering | Second: after data foundation exists | Models stay in notebooks, never reach production |
MLOps Engineer | Deploy, monitor, retrain models in production | Head of Engineering | Third: before first production deployment | Manual, high-risk, unrepeatable deployments |
AI / Model Risk Lead | Governance, audit trails, explainability, compliance | CRO / Chief Data Officer | Fourth: before go-live, not after | Regulatory exposure, no accountable governance owner |
AI Product Owner | Ties model outputs to business outcomes | Business unit head | Fifth: anchors the use case from Step 1 onward | Technically successful models that deliver no business value |
Real-World Use Cases: AI Team Structure in Practice
Use Case 1: Regional Bank, Credit Risk Function (BFSI)
A Singapore-based bank initially hired three data scientists to build an AI credit scoring model with no dedicated data engineering or MLOps support. After 14 months, the model existed only in a research environment with no path to production and no governance documentation. Restructuring around the five-role framework adding a data engineer, an MLOps engineer, and a named model risk lead reduced time to MAS-aligned production deployment to 7 months from that restructuring point. The AI/model risk lead role proved decisive: it was the function that produced the audit trail documentation the bank's compliance team required before any production sign-off.
Use Case 2: Logistics Enterprise, Demand Forecasting (General Enterprise)
A regional logistics company built its AI team in the correct sequence from the start: two data engineers first, followed by ML engineers, then an MLOps engineer before the first production deployment. No dedicated AI/model risk lead was needed at launch, given the non-regulated use case, but a part-time governance function was assigned to the AI product owner. First production model shipped in 8 months. The structured sequencing data, then models, then operations, then governance proportional to risk reflects how AI development team roles should scale with regulatory exposure, not be applied uniformly regardless of use case.
AI Implementation Playbook Get the complete role-by-role hiring sequence, job descriptions, and reporting structure templates for building your AI engineering team. Download free →
Key Risks and Failure Modes in AI Team Structure
Hiring ML engineers before data engineers: the single most common structural error; models cannot be built reliably without governed data pipelines in place first
No named model risk owner: governance treated as a shared responsibility across the team often means no one is actually accountable when a regulator or auditor asks
MLOps treated as an afterthought: teams that skip dedicated MLOps roles end up with manual, undocumented deployment processes that do not scale past the first model
Product owner reporting only into engineering: disconnects AI development from business outcome accountability, producing technically impressive models with no measurable ROI
Flat team structure with no sequencing: hiring all five role types simultaneously without a phased build creates coordination overhead before any foundation exists to coordinate around
A structured AI transformation roadmap template helps sequence these hires correctly against your organisation's specific use case timeline, rather than hiring reactively.
Decision Framework: How to Size Your AI Engineering Team Structure
Build a full five-role team when:
You have board-approved budget for a 12+ month AI program with multiple use cases
At least one use case touches regulated data or decisions (credit, claims, hiring, healthcare)
You expect to deploy more than one production model within 18 months
Start with a minimal three-role core (data engineer, ML engineer, MLOps engineer) when:
You are validating a single, well-scoped use case before committing to a full team
The use case is non-regulated and lower risk
You plan to engage external governance support rather than hiring a full-time risk lead immediately
Use a hybrid model internal product and governance ownership, external engineering execution when:
You need production AI within 12 months but lack internal AI engineering capacity today
You want to retain accountability internally while building capability progressively
Samta.ai's TATVA hiring assessment platform supports this hiring sequence directly, using adaptive, role-specific assessment to evaluate candidates for each of these five AI engineering role categories rather than applying generic technical screening across all of them. Compare this approach to traditional hiring platforms to understand why role-specific assessment matters more for AI engineering hires than for general software roles.
Conclusion
AI engineering team structure determines whether AI initiatives reach production or stall indefinitely in pilot purgatory. The five-role framework data engineers, ML engineers, MLOps engineers, an AI/model risk lead, and an AI product owner sequenced correctly, is what separates enterprises that ship production AI from those that accumulate proof-of-concepts.Hire in the right order, govern from day one, and tie every role back to a defined business outcome from the start.
Book a Consultation Speak with a Samta.ai specialist to map the right AI engineering team structure and hiring sequence for your organisation →

About Samta
Samta.ai is a Singapore-headquartered AI Product Engineering & Data Intelligence partner helping enterprises build production-grade AI systems for regulated and data-intensive environments.We help organizations move beyond experimentation by engineering scalable, explainable, and enterprise-ready AI solutions from data foundations and model development to workflow automation and deployment.
Our capabilities combine deep AI expertise, data engineering, and product engineering to deliver measurable business impact across FinTech, BFSI, cybersecurity, regulatory technology, and enterprise operations.
Our enterprise AI products power real-world intelligence systems:
• TATVA : AI-driven data intelligence platform for governed analytics, monitoring, and operational insights
• VEDA : Explainable and audit-ready AI decisioning engine built for compliance-sensitive enterprise workflows
• CORA-Property Management Solutions: : Predictive intelligence platform for real-estate pricing, portfolio optimization, and investment analytics
Backed by ecosystem partnerships with Microsoft, Databricks, Snowflake, and AWS, Samta.ai delivers agile, cost-efficient AI engineering with faster turnaround and enterprise-grade scalability. Trusted by enterprises across FinTech, BFSI, and digital transformation initiatives, Samta.ai embeds AI governance, data privacy, and compliance-by-design principles directly into the AI lifecycle , enabling organizations to scale AI with transparency, accountability, and operational control.
Enterprises leveraging Samta.ai automate 65%+ of repetitive data, analytics, and decision workflows while maintaining governance, explainability, and measurable business outcomes. Samta.ai provides the strategic consulting, AI engineering, and data modernization expertise needed to align enterprise operations with next-generation AI transformation goals.
Frequently Asked Questions
What roles make up a typical AI engineering team structure?
A production-ready AI engineering team structure includes five core roles: data engineers who build the data foundation, ML engineers and data scientists who develop models, MLOps engineers who deploy and monitor them in production, an AI or model risk lead who owns governance and compliance, and an AI product owner who ties model outputs to business value. Smaller organisations may combine roles, but all five functions need to be covered before production deployment.
In what order should I hire for an AI engineering team?
Hire data engineers first to establish a governed data foundation, followed by ML engineers and data scientists to develop models. Bring in an MLOps engineer before your first production deployment, not after. For regulated industries, name an AI or model risk lead before go-live. The AI product owner role should be defined from the start of the program, even if filled by an existing business stakeholder initially.
How is AI being used in hiring for AI engineering roles themselves?
Organisations are increasingly using AI in hiring to assess AI engineering candidates — applying adaptive, role-specific assessment models rather than generic technical interviews. Given how scarce and expensive senior ML engineers, MLOps specialists, and AI governance leads have become in APAC, structured assessment that accurately differentiates between these distinct role types has become a meaningful competitive advantage in talent acquisition.
Does every organisation need a dedicated AI or model risk lead?
Not every organisation needs a full-time AI or model risk lead immediately, but every organisation deploying AI in regulated contexts credit decisions, insurance underwriting, hiring, healthcare does. For lower-risk, non-regulated use cases, governance responsibility can initially sit with the AI product owner or be supported externally, but it should never be left genuinely unowned.
How does an AI engineering team structure differ from a standard agile engineering team structure?
A standard agile engineering team structure typically includes product, engineering, and QA roles working in sprints against defined features. An AI engineering team requires two additional layers a standard team does not: a data foundation layer (data engineers) and a governance layer (AI/model risk lead), both of which sit upstream and alongside the development cycle rather than within a standard sprint structure.